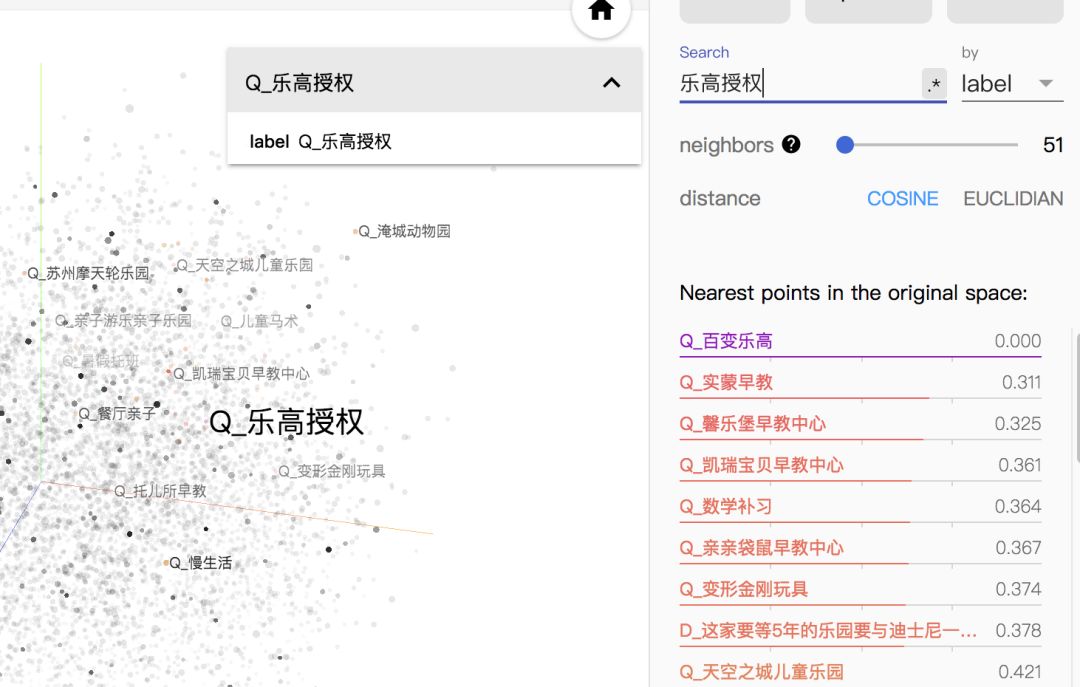
图4 dssm 模型效果 可以看到模型训练出的语义空间,在图4中对于 query“乐高授权”,余弦相似度推荐的 query 或内容在语义上都存在较高的相关性。

百练成钢 高中文言语义脉络训练 高二 高三适用 附带参考答案

百练成钢 高中文言语义脉络训练 高二 高三适用 附带参考答案

百练成钢 高中文言语义脉络训练 高二 高三适用 附带参考答案

百练成钢 高中文言语义脉络训练 高二 高三适用 附带参考答案

百练成钢 高中文言语义脉络训练 高二 高三适用 附带参考答案
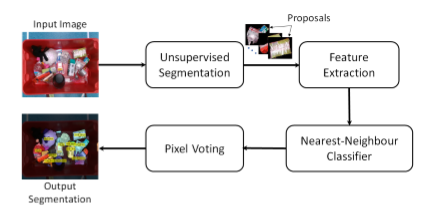
对有限训练数据进行语义分割

caffe初步实践 使用训练好的模型完成语义分割任务

caffe初步实践 使用训练好的模型完成语义分割任务

caffe初步实践 使用训练好的模型完成语义分割任务
ubnuntu16.04下caffe初步实践 使用训练好模型完成语义分割任务
caffe初步实践 使用训练好的模型完成语义分割任务
图像分割损失函数 语义分割模型在训练过程中通常使用一个简单的交叉分类熵损失函数。

使用libtorch读取预训练权重,完成语义分割

作为一个开放的平台,开发者可以通过dolphin.ai平台免费完成语义训练,从而获得专属的语义分析服务(如果语义分析所需计算资源较大则需另外付费)。

其中,在第4种学习策略中,有两种训练策略: 4.1:损失函数为语义分割预测损失和变化检测预测损失的加权和,通过遍历找到最合适的超参数(损失权重) 4.2:先单独学习语义分割分支,然后固定该分支后,在学习变化检测分支 1.提出1个用于变化检测的数

使用libtorch读取预训练权重,完成语义分割

使用libtorch读取预训练权重,完成语义分割

dssm:一个相似驱动sent2vec模型 初始化:神经网络使用随机权重进行初始化 训练:在语义矢量之间计算余弦相似度 深度架构语义模型/深度语义相似
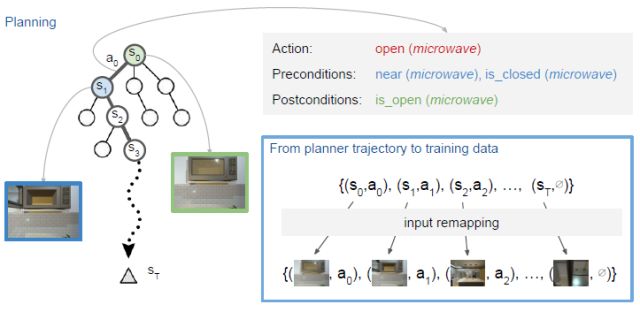
基于深度后继表示的视觉语义规划 iccv2017 49